Bidirectional LSTM
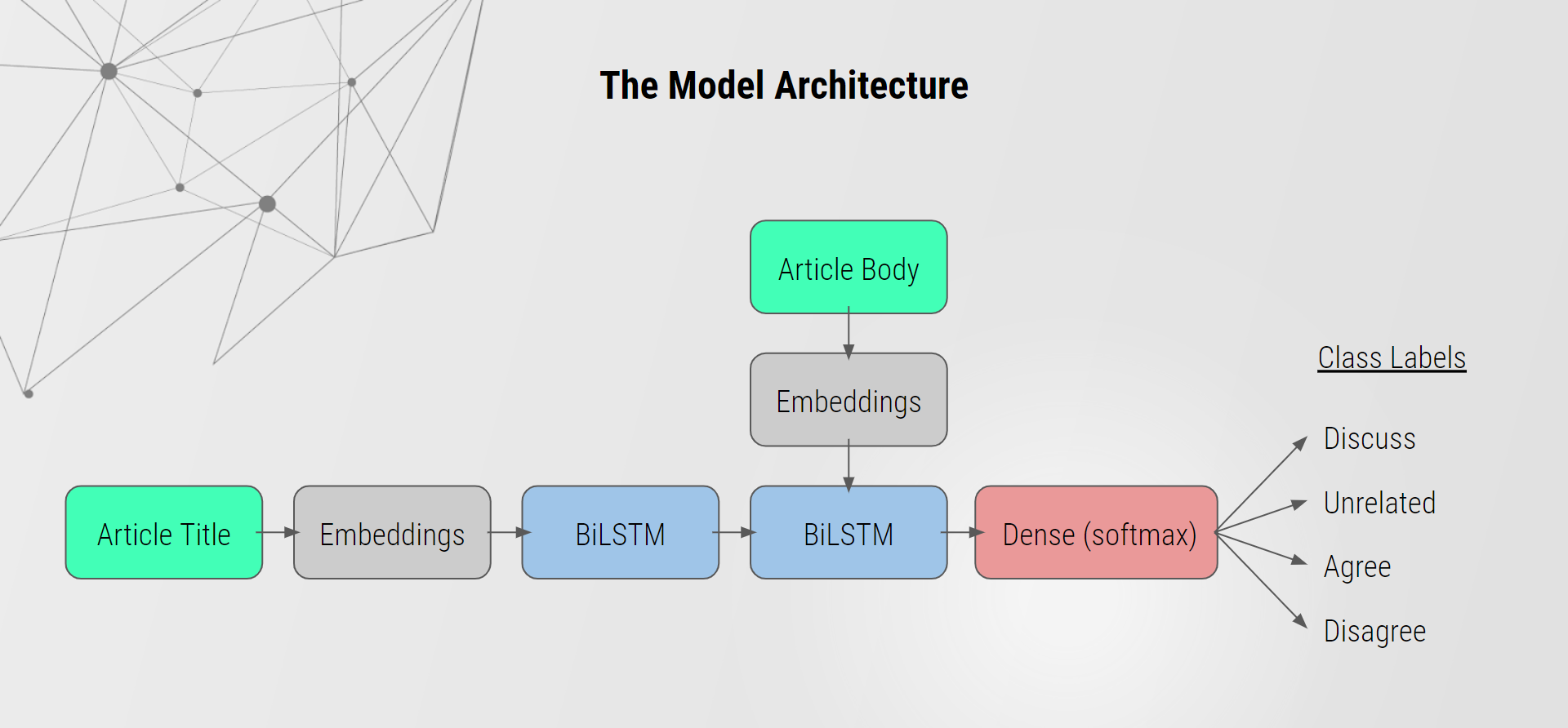
Word Embeddings
We used Global Vector (GloVe) embeddings to embed our text data into numerical data. GloVe is an unsupervised learning algorithm developed at Stanford for obtaining vector representations for words.
Hyperparameters
We trained the model for 20 epochs using the Adam optimizer with a learning rate of 0.001.

Class Weights
We created and assigned class weights during training to account for the uneven distribution of training data, as there were far more "discuss" and "unrelated" articles than there were "agree" and "disagree" articles.