BERT
What is BERT?
BERT stands for Bidirectional Encoder Representations from Transformers.
BERT is an open-source NLP model pretrained on a large dataset of text (including books, WIkipedia, etc.)
BERT uses Transformer, an attention mechanism that learns contextual relations between words & sentences, to determine the most relevant parts of the input sequence.
Attention Mechanisms
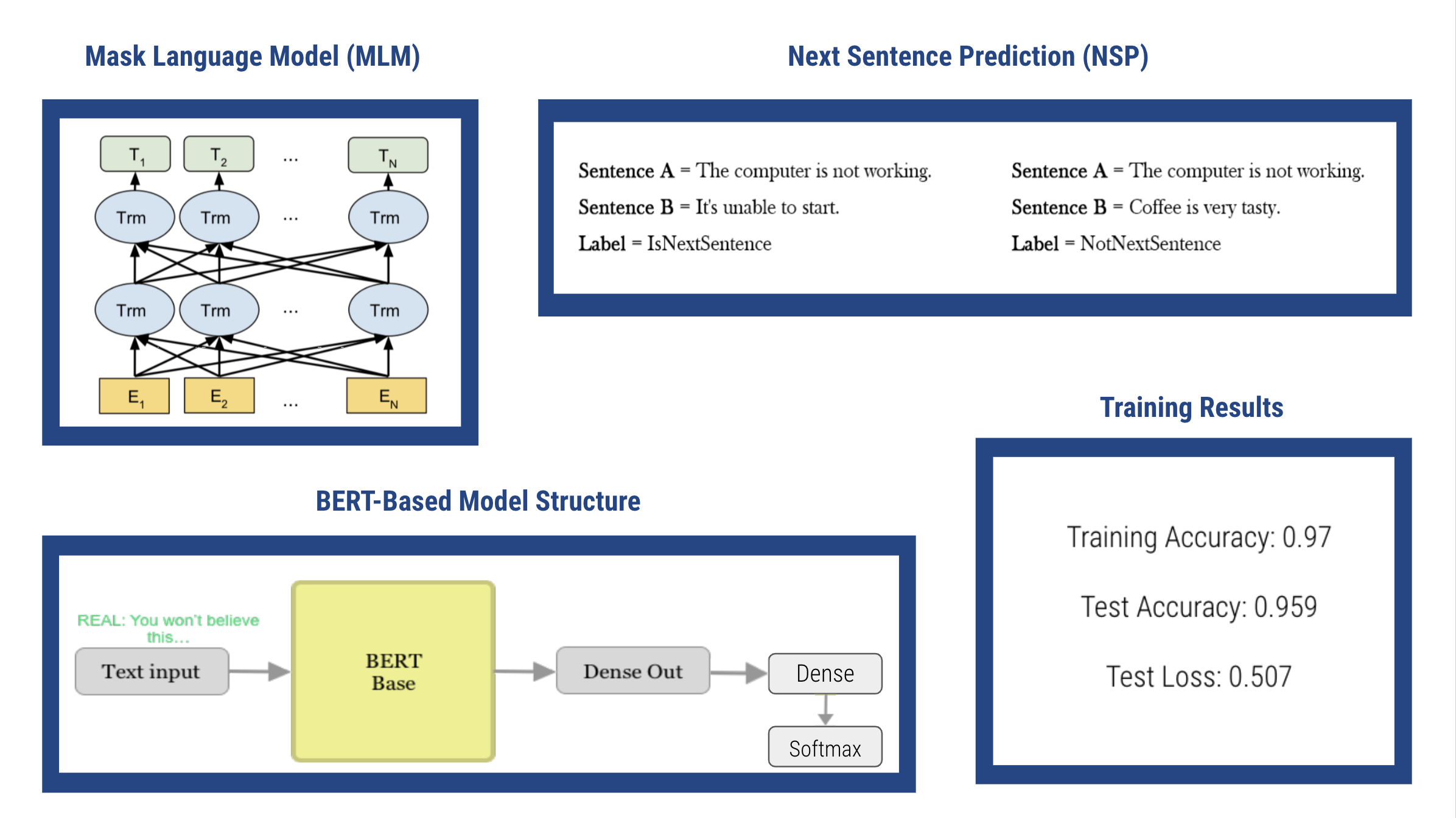
Mask Language Model (MLM): By using MLM, BERT learns to model relstionships between words. BERT masks out 15% of the input words, then conditions each word bidirectionally to predict masked words. The model attempts to predict the original value of masked words.
Next Sentence Prediction (NSP): By using NSP, BERT learns to model relstionships between sentences. BERT is provided pairs of sentences as input, then learns to predict if the given second sentence is a subsequent sentence in the context.
BERT-Based architecture
Our model fine-tunes the pre-trained BERT model using the concept of transfer learning.
BERT Base: 12 layers (transformer blocks), 12 attention heads, and 110 million parameters
Additional Layers added: Dense layer & Softmax layer.